

Introduction
Red Hat OpenShift Container Platform is a security-centric and enterprise-grade hardened Kubernetes platform for deploying and managing Kubernetes clusters at scale, developed and supported by Red Hat. Red Hat OpenShift Container Platform includes enhancements to Kubernetes so users can easily configure and use GPU resources for accelerating workloads such as deep learning.
The GPU operator manages NVIDIA GPU resources in a Openshift cluster and automates tasks related to bootstrapping GPU nodes. Since the GPU is a special resource in the cluster, it requires a few components to be installed before application workloads can be deployed onto the GPU. These components include the NVIDIA drivers (to enable CUDA), Kubernetes device plugin, container runtime and others such as automatic node labelling, monitoring etc.
The NVIDIA GPU Operator uses the operator framework within Kubernetes to automate the management of all NVIDIA software components needed to provision GPU. These components include the NVIDIA drivers (to enable CUDA), Kubernetes device plugin for GPUs, the NVIDIA Container Toolkit, automatic node labelling using GFD, DCGM based monitoring and others.
Prerequisites
Before following the steps in this guide, ensure that your environment has:
- A working OpenShift cluster up and running with a GPU worker node. See OpenShift Container Platform installation for guidance on installing. Refer to Container Platforms for the support matrix of the GPU Operator releases and the supported container platforms for more information.
- Access to the OpenShift cluster as a cluster-admin to perform the necessary steps.
- OpenShift CLI (oc) installed.
- RedHat Enterprise Linux (RHEL) 8.X
- Ensure that the appropriate Red Hat subscriptions and entitlements for OpenShift are properly enabled. For more details on enabling entitlements please refer Step 1 and Step 2 in this page
- Install the Node Feature Discovery (NFD) operator using Step 3 of this page
- API Key to access images from icr.io. If you dont have one, request api key to access icr.io to pull images at following email address rocketce@rocketsoftware.com. For more details refer IBM Cloud Docs .
Verification of Prerequisites
1. Verify entitlements
# oc get machineconfig | grep entitlement 50-entitlement-key-pem 2.2.0 4d1h 50-entitlement-pem 2.2.0 4d1h
# oc get mcp NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-30627edc9bc847e2f6a7a9755561f65c True False False 3 3 3 0 24d worker rendered-worker-8d10dd8f6569ba1505d831e95a6b7d6c True False False 4 4 4 0 24d
2. Verify Node Feature Discovery (NFD) operator is installed
NFD can be validated by checking in web console under the menu Operators -> Installed Operators.Also the below command can be run to check using CLI.
# oc get deployment -n openshift-operators
NAME READY UP-TO-DATE AVAILABLE AGE
nfd-controller-manager 1/1 1 1 2d22h
Deployment steps
The preferred method to deploy the GPU Operator is using helm.
1. Create Project:
Create a project using Openshift console which will be used to create the resources of Gpu operator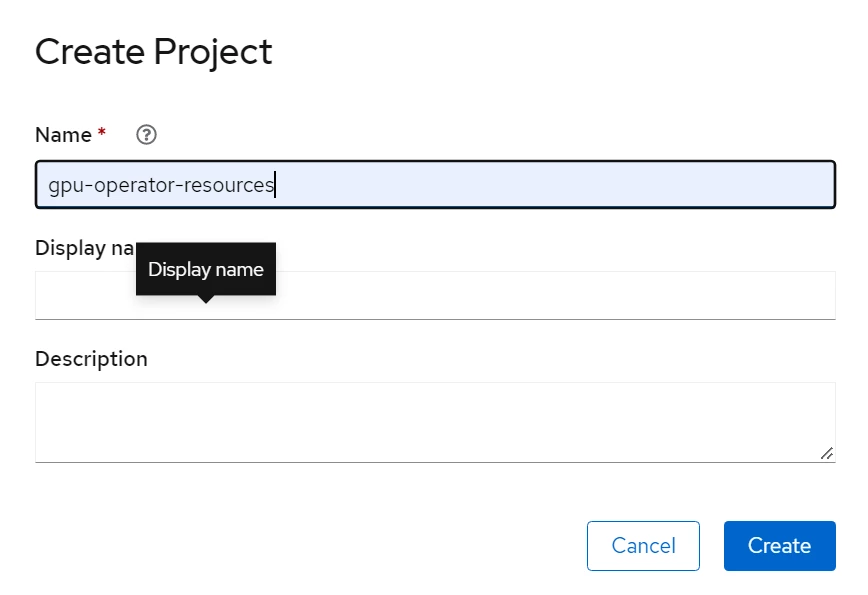
2. Install Helm:
Below is the command to install helm

To validate helm installation, below command should be returning a table if helm is installed successfully
helm list
3. Add Rocket Helm repository for Gpu Operator
Now, add the Rocket Helm repository for Gpu Operator:

To validate repo addition, below command should list the added rocketgpu
helm repo list
4. Create an image pull secret to store the API key credentials

b) Verify the secret creation, below command gives list of secrets in the namespace. The name "icrlogin" must be present there.
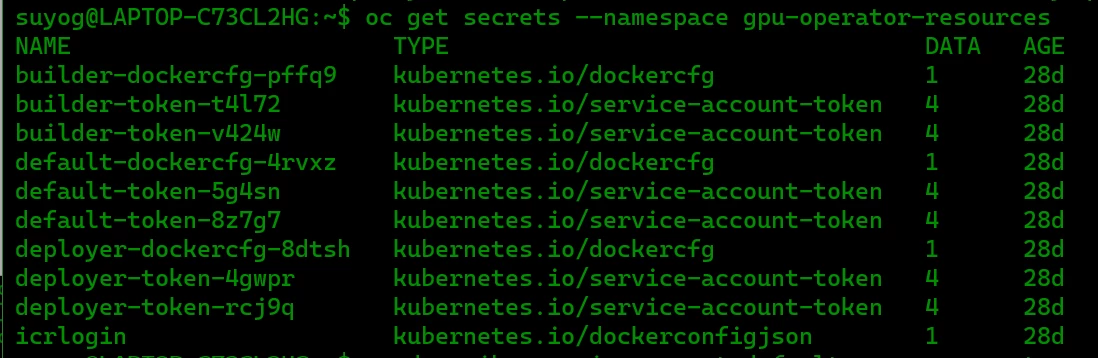
c) Store the image pull secret in the Kubernetes service account for the selected project. Every OpenShift project has a Kubernetes service account that is named default. Within the project, you can add the image pull secret to this service account to grant access for pods to pull images from your registry. Deployments that do not specify a service account automatically use the default service account for this OpenShift project.

e) Verify that your image pull secret was added to your default service account.
Example output
5. Installation of GPU Operator
Installation of GPU Operator can be done using the below command. This will use the default configurations.
helm install --wait --generate-name rocketgpu/gpu-operator -n <project_name>
The GPU Operator Helm chart offers a number of customizable options that can be configured depending on your environment.
Chart Customization Options:
The following options are available when using the Helm chart. These options can be used with --set when installing via Helm.
|
Parameter |
Description |
Default |
|
nfd.enabled |
Deploys Node Feature Discovery plugin as a daemonset. Set this variable to false if NFD is already running in the cluster. |
true |
|
operator.defaultRuntime |
By default, the operator assumes your Kubernetes deployment is running with docker as its container runtime. Other values are either crio (for CRI-O) or containerd (for containerd). |
docker |
|
mig.strategy |
Controls the strategy to be used with MIG on supported NVIDIA GPUs. Options are either mixed or single. |
single |
|
psp.enabled |
The GPU operator deploys PodSecurityPolicies if enabled. |
false |
|
driver.enabled |
By default, the Operator deploys NVIDIA drivers as a container on the system. Set this value to false when using the Operator on systems with pre-installed drivers. |
true |
|
driver.repository |
The images are downloaded from NGC. Specify another image repository when using custom driver images. |
icr.io/rocketce |
|
driver.version |
Version of the NVIDIA datacenter driver supported by the Operator. |
Depends on the version of the Operator. See the Component Matrix for more information on supported drivers. |
|
driver.rdma.enabled |
Controls whether the driver daemonset should build and load the nvidia-peermem kernel module. |
false |
|
toolkit.enabled |
By default, the Operator deploys the NVIDIA Container Toolkit (nvidia-docker2 stack) as a container on the system. Set this value to false when using the Operator on systems with pre-installed NVIDIA runtimes. |
true |
|
migManager.enabled |
The MIG manager watches for changes to the MIG geometry and applies reconfiguration as needed. By default, the MIG manager only runs on nodes with GPUs that support MIG (for e.g. A100). |
true |
The above parameters can be used to customize the installation. For example if the user has already pre-installed NVIDIA drivers as part of the system image:
helm install --wait --generate-name rocketgpu/gpu-operator --set driver.enabled=false
In another scenario if you want to install gpu operator with specific version and use secrets to pull image
6. Verify the successful installation of the NVIDIA GPU Operator
The commands below describe various ways to verify the successful installation of the NVIDIA GPU Operator.
oc get pods,daemonset -n gpu-operator-resources
|
NAME |
READY |
STATUS |
RESTARTS |
AGE |
|
pod/gpu-feature-discovery-vwhnt |
1/1 |
Running |
0 |
6m32s |
|
pod/nvidia-container-toolkit-daemonset-k8x28 |
1/1 |
Running |
0 |
6m33s |
|
pod/nvidia-cuda-validator-xr5sz |
0/1 |
Completed |
0 |
90s |
|
pod/nvidia-dcgm-5grvn |
1/1 |
Running |
0 |
6m32s |
|
pod/nvidia-dcgm-exporter-cp8ml |
1/1 |
Running |
0 |
6m32s |
|
pod/nvidia-device-plugin-daemonset-p9dp4 |
1/1 |
Running |
0 |
6m32s |
|
pod/nvidia-device-plugin-validator-mrhst |
0/1 |
Completed |
0 |
48s |
|
pod/nvidia-driver-daemonset-pbplc |
1/1 |
Running |
0 |
6m33s |
|
pod/nvidia-node-status-exporter-s2ml2 |
1/1 |
Running |
0 |
6m33s |
|
pod/nvidia-operator-validator-44jdf |
1/1 |
Running |
0 |
6m32s |
|
NAME |
DESIRED |
CURRENT |
READY |
UP-TO-DATE |
AVAILABLE |
NODE SELECTOR |
AGE |
|
daemonset.apps/gpu-feature-discovery |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.gpu-feature-discovery=true |
6m32s |
|
daemonset.apps/nvidia-container-toolkit-daemonset |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.container-toolkit=true |
6m33s |
|
daemonset.apps/nvidia-dcgm |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.dcgm=true |
6m33s |
|
daemonset.apps/nvidia-dcgm-exporter |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.dcgm-exporter=true |
6m33s |
|
daemonset.apps/nvidia-device-plugin-daemonset |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.device-plugin=true |
6m33s |
|
daemonset.apps/nvidia-driver-daemonset |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.driver=true |
6m33s |
|
daemonset.apps/nvidia-mig-manager |
0 |
0 |
0 |
0 |
0 |
nvidia.com/gpu.deploy.mig-manager=true |
6m32s |
|
daemonset.apps/nvidia-node-status-exporter |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.node-status-exporter=true |
6m34s |
|
daemonset.apps/nvidia-operator-validator |
1 |
1 |
1 |
1 |
1 |
nvidia.com/gpu.deploy.operator-validator=true |
6m33s |
7. Running Sample GPU Applications using a sample pod
Create a sample pod as mentioned below and validate the successful installation of Gpu operator.
cat<< EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-operator-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "quay.io/mgiessing/cuda-sample:vectoradd-cuda11.2.1-ubi8"
resources:
limits:
nvidia.com/gpu: 1
EOF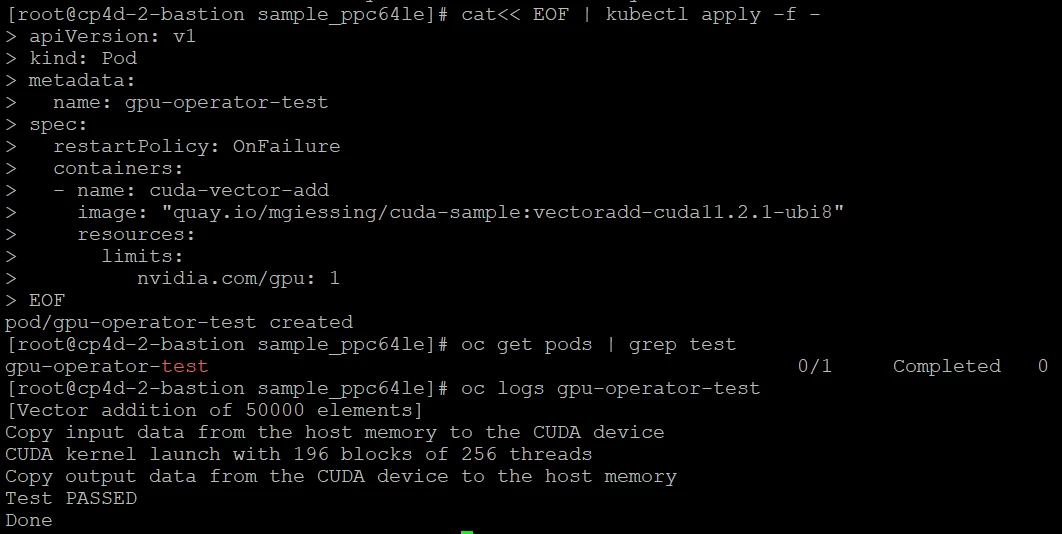
8. Running Sample GPU Applications using a sample deployment
We can apply a sample deployment file and verify the logs after the pod is in running state.[root@cp4d-2-bastion sample_ppc64le]# cat cuda-demo1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: cuda-demo
spec:
replicas: 1
selector:
matchLabels:
app: cuda-demo
template:
metadata:
labels:
app: cuda-demo
spec:
selector:
matchLabels:
app: cuda-demo
containers:
- name: cuda-demo
image: nvidia/cuda-ppc64le:11.4.0-runtime
command: ["/bin/sh", "-c"]
args: ["nvidia-smi && tail -f /dev/null"]
resources:
limits:
nvidia.com/gpu: 1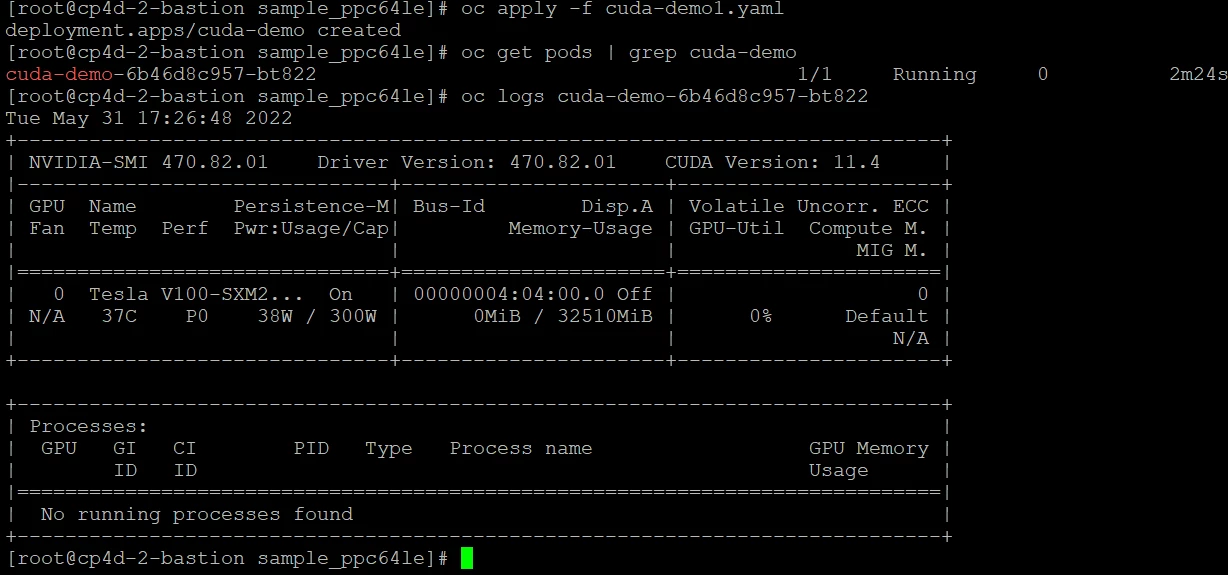
9. Uninstall
To uninstall the operator:
helm delete -n gpu-operator $(helm list -n gpu-operator | grep gpu-operator | awk '{print $1}')
You should now see all the pods being deleted:
oc get pods -n gpu-operator-resources
No resources found.
Also, ensure that CRDs created during the operator install have been removed:
oc get crds -A | grep -i clusterpolicies.nvidia.com
and
oc delete crd clusterpolicies.nvidia.com
Note:
After un-install of GPU Operator, the NVIDIA driver modules might still be loaded. Either reboot the node or unload them using the following command:
sudo rmmod nvidia_modeset nvidia_uvm nvidia
------------------------------
Uvaise Ahamed
Rocket Internal - All Brands
------------------------------

