

Hi,
I need to add special character to my app. set of special characters. It is Ć (C accent aigu). But this special character is not in the ASCII table unlike other special characters used in my app. And using windows character map to add the Ć for example in to the created xml file report is causing troubles. It looks like this:
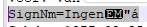
How can I handle this special char. in my app?

