we have a file that has a MV list of part numbers in an attribute
In D3, we used to be able to select wo "235789" PL.IDS
this would give is the keys to a new file. The dictionary looks like:
DICT wo pl.ids
01: S
02: 19
03:
04:
05:
06:
07:
08: F;"*"R;19;:;0R;_;:
09: L
10: 28
11: A;0R:"*"R:N(PICKLIST.PNS) ~~ F;0;"*"R;:;19;:
In D3, we would get
235789*001
235789*002
235789*003
In QM, we get
235789*001
002
003
Yes, we already use indexes though out our system, but we have some of this old logic. We are hunting this down, but we would like to know to make the dictionary work correctly. We have tried the "A" correlative, but neither seems to work.
------------------------------
Jesse Tillia
Proman-ERP, Inc.
West Seneca NY US
------------------------------
Assuming I understand your F-correlative correctly (but it is a long time since I used either A or F correlatives), I would use something like this:
First, create a field defining your attribute 19:
DICT BS.TEMP PL.IDS
1: D
2: 19
3:
4: PL ids
5: 7R
6: M
7: A-PL
Now, create an I-type that splices the order id onto those ids:
DICT BS.TEMP ORDER.PL.IDS
1: I
2: SPLICE(REUSE(@ID), '*', PL.IDS)
3:
4: Order PL ids
5: 12L
6: M
7: A-PL
Now, list your file:
LIST BS.TEMP PL.IDS ORDER.PL.IDS
BS.TEMP... PL ids. Order PL ids
1 001 1*001
002 1*002
002 1*002
Note: Both dictionaries are defined a "multi-valued" (field 6) and have an "association" defined (field 7) so the query processor knows that the multivalues in these fields are related.
I hope this helps.
Brian
------------------------------
Brian Speirs
Wellington NZ
------------------------------
Assuming I understand your F-correlative correctly (but it is a long time since I used either A or F correlatives), I would use something like this:
First, create a field defining your attribute 19:
DICT BS.TEMP PL.IDS
1: D
2: 19
3:
4: PL ids
5: 7R
6: M
7: A-PL
Now, create an I-type that splices the order id onto those ids:
DICT BS.TEMP ORDER.PL.IDS
1: I
2: SPLICE(REUSE(@ID), '*', PL.IDS)
3:
4: Order PL ids
5: 12L
6: M
7: A-PL
Now, list your file:
LIST BS.TEMP PL.IDS ORDER.PL.IDS
BS.TEMP... PL ids. Order PL ids
1 001 1*001
002 1*002
002 1*002
Note: Both dictionaries are defined a "multi-valued" (field 6) and have an "association" defined (field 7) so the query processor knows that the multivalues in these fields are related.
I hope this helps.
Brian
------------------------------
Brian Speirs
Wellington NZ
------------------------------
This works perfectly. As we came from the D3 world, we were used to A and S items. We have only used a few I dictionary items on anything new.
I made two new dictionary items from your example.
:ct dict wo pl.ids.qm
DICT wo pl.ids.qm
1: I
2: SPLICE(REUSE(@ID),'*',PL.IDS.NEW)
3:
4: PL IDS QM
5: 12L
6: M
7: A-PL
and then
:ct dict wo pl.ids.new
DICT wo pl.ids.new
1: D
2: 19
3:
4: pl ids
5: 7R
6: M
7: A-PL
now I select my WO file
SELECT WO "1126" PL.IDS.QM
and list my PL file with these new keys
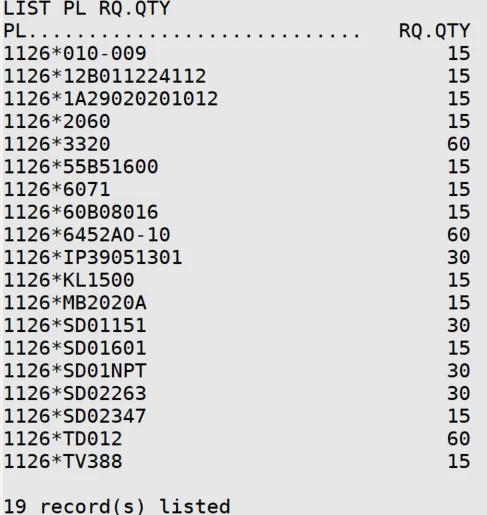
perfect.
Thanks
------------------------------
Jesse Tillia
Proman-ERP, Inc.
West Seneca NY US
------------------------------
This works perfectly. As we came from the D3 world, we were used to A and S items. We have only used a few I dictionary items on anything new.
I made two new dictionary items from your example.
:ct dict wo pl.ids.qm
DICT wo pl.ids.qm
1: I
2: SPLICE(REUSE(@ID),'*',PL.IDS.NEW)
3:
4: PL IDS QM
5: 12L
6: M
7: A-PL
and then
:ct dict wo pl.ids.new
DICT wo pl.ids.new
1: D
2: 19
3:
4: pl ids
5: 7R
6: M
7: A-PL
now I select my WO file
SELECT WO "1126" PL.IDS.QM
and list my PL file with these new keys
perfect.
Thanks
------------------------------
Jesse Tillia
Proman-ERP, Inc.
West Seneca NY US
------------------------------
Hi Jesse,
My advice would be to embrace I-types for your calculations. This is partly because QM does not fully support A/S types (e.g. LPV is not supported), but mostly because the expressions in I-types are much more readable than A or F correlatives.
We started in MV using the ADDS products, then mvBASE, then UniVerse, and now QM (over a 40 year period). Along the way, we have migrated most of our dictionaries to D and I-types, and many queries are much more readable and sensible than they were in the PICK days.
If you define your dictionaries nicely, you can use the GENERATE command to generate an INCLUDE item for your QMBasic programs that define the record the layout for each file. Then you can use those included tokens in your programs, and the programs (a) become more readable; and (b) you have less chance of specifying an incorrect attribute number when accessing a record.
The ITYPE function is also great for getting a value from the database from within your programs.
Feel free to contact me if you have any (more) questions.
Cheers,
Brian
------------------------------
Brian Speirs
Wellington NZ
------------------------------
