


Starting with a RM idxformat 21 file. Loading text data, encountering an extended ascii character (value above ascii 127).
Debug step in Visual Studio, value is as appears in the original file.

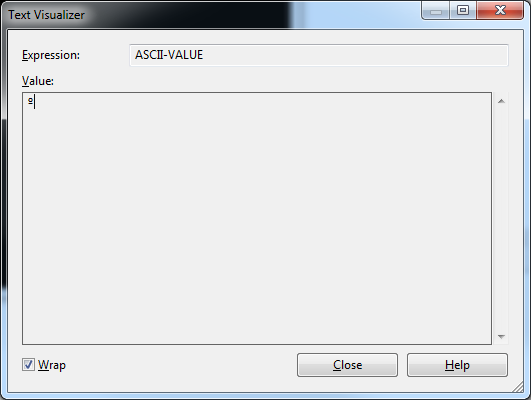
Debug window with value of ASCII-VALUE

This is the entire record, where the character is.
After moving that record to a location in Working Storage, that record is written. This is the code in that section:
if WORK-FIELD3(WS-SUB1:1) < SPACE or WORK-FIELD3(WS-SUB1:1) > "~" then
MOVE WORK-FIELD3(WS-SUB1:1) TO ASCII-VALUE
move spaces to special-characters-record
move ASCII-VALUE to special-character
move SF-AR-PRIMARY-KEY to special-character-agr
move WORK-FIELD3 to special-character-rec
move DUMMY-FIELD-NAME to special-character-rec-name
move special-characters-line to special-characters-record
write special-characters-record
display "special character: " ASCII-VALUE
display "agreement = " SF-AR-PRIMARY-KEY
move "?" to WORK-FIELD4(WS-SUB2:1)
end-if
(I would prefer to not replace the character, this is just what I'm doing right now)
Directives at the top of the program:
$SET IDXFORMAT"21"
$SET DIALECT"RM"
After write, this is the line that remains. The special character has switched values (this is an error logging record)
§ 174204001A AV. LA FONTANA N§ 1155 INT.01 SF-AR-INV-LINE-2
§ 174204002A AV. LA FONTANA N§ 1155 INT. 01 SF-AR-INV-LINE-2
Query the database using SQL Management Studio, for the values of the characters.

This value is stored in a database. What is happening is when we retrieve that text field, and put that in a string variable (which rebuilds the COBOL record) value 167 isn’t being displayed, shortening the text field by one, and throwing off the entire subsequent fields by 1.
Is there any way to retain the original value? Or are we going to have to replace all extended ASCII characters with something else?
