
Hello
I'm testing iCLuster in a pre-production machine by restoring a lot of updated files from User Acceptance Test system to pre-PRD system while turning off replication group. Then run DMMRKPOS and start the group with the marked position *YES. Then I start Sync Check on the group and found around 3,000 OOS objects reported :
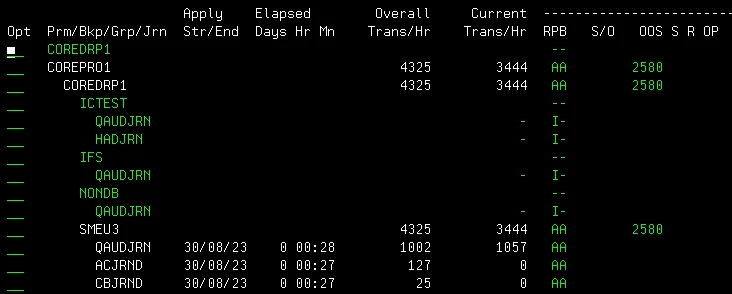
When I do WRKACTJOB on primary system, there are several iCluster jobs running eating up a total of not more than 35% CPU power of P9 2-core PRD machine. CPU % Busy is less than 10% on the backup node DR machine (same HW capacity as PRD). When I press F5, the OOS count reduce slowly.
My question is whether there is a way available in iCluster's parameters that I can, say, increase the number of iCluster jobs doing OOS Activation task to speed up the process?
Thanks in advnace for your response.
------------------------------
Satid Singkorapoom
IBM i SME
Rocket Forum Shared Account
------------------------------




